Datenaufbereitung mit Excel
Sitzungsdaten aus Biotrace exportieren und in Exceltabelle anzeigen
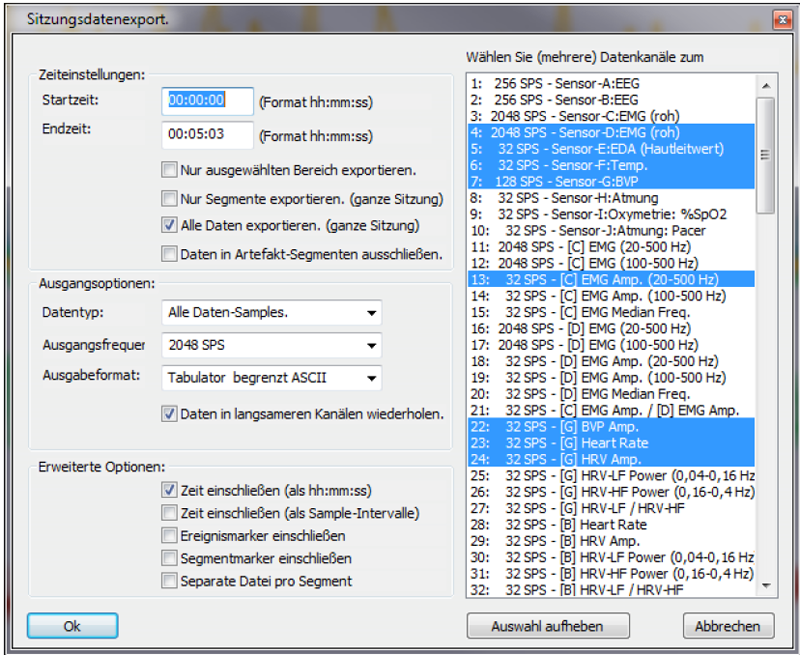
In Biotrace: Über Datei -> Sitzungsdaten exportieren öffnet sich das Exportfenster (wenn man alle Daten einer Sitzung exportieren möchte, bzw. via Auswahl eines Abschnitts und "ausgewählte Daten exportieren" auswählen), mit der Möglichkeit, die Kurven als Textfiles zu exportieren (tab, csv oder oder Matlab), und sie in Excel o.ä. weiter zu verarbeiten:
Biotrace+
Datenexportfenster
Zum
Export die zu exportierenden Kanäle auswählen
(meist: 3:EMG, 4:EMG (für Audio), 5:EDA (Hautleitwert), 6:Temp.,
7:BVP, 8:Atmung, 22:BVP Amp. 23:Heart Rate, 24:HRV Amp.)
Ausgangsfrequenz einstellen (2048, falls Musik über
die EMG-Kanäle mitaufgenommen wurde, sonst auch 128 oder 32 SPS).
"Tabulator begrenzt ASCII" wählen, damit die Daten in Excel
weiter verarbeitet werden können.
"Daten in langsameren Kanälen wiederholen" ankreuzen, ebenso
Zeit, Ereignis- und Segmentmarker möglichst beim Export einschließen.
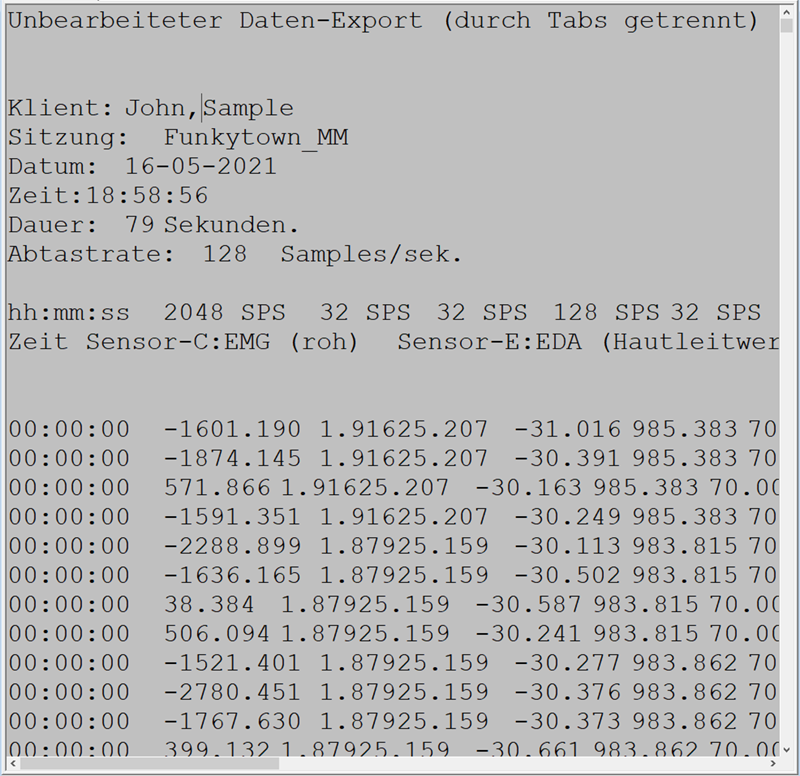
Export in eine Textdatei (Kommata getrennt ASCII).
Excel öffnen, die Dateiendung der exportierten Datei von *.txt nach *.tsv (tab separated values) umbenennen und in das geöffnete Excel ziehen.
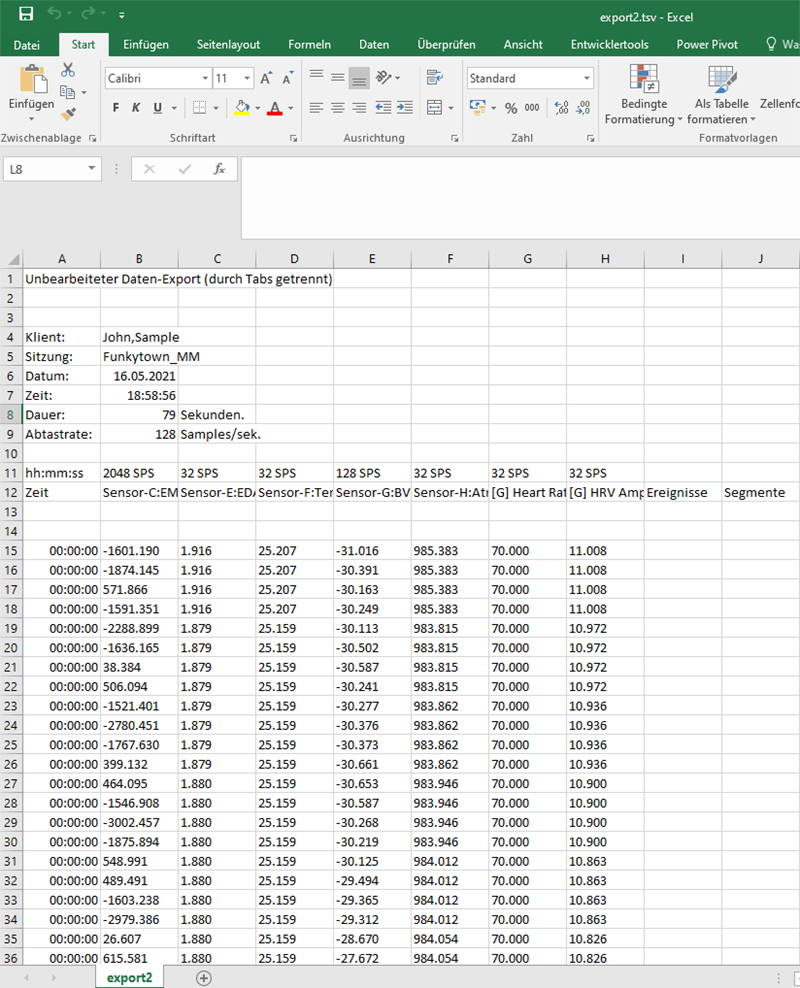
tsv-Datei als Biotrace-Export in Excel
Beim Export werden anstelle von Kommata Punkte bei Zahlenwerten ausgegeben. Diese müssen in Excel durch Suchen/ersetzen in Kommata verwandelt werden, damit Excel die Zahlen auch als Zahlen erkennt.
Sobald die Daten in Excel als Zahlen vorliegen (z.B. aus den Messungen zu den physiologischen Daten beim Hören eines Lieds hervorgegangenen Exporten export1.txt und export2.txt zusammengefasst in der Excel-Datei export.xlsx), können sie auch in ein ein Javascript-Array konvertiert werden (z.B. biotrace_array.js) und als Grundlage für eine interaktive Datenvisualisierung mit Plotly eingesetzt werden (Gesamtpaket unter biotrace_plotly.zip).
Daten aus Biotrace an der Audiospur orientieren
Meist sind die Biotrace gewonnenen Tabellen viel zu groß und man braucht nur den Teil, in dem das Musikstück bzw. Klänge oder Geräusche auf der Audiospur zu sehen sind. Um hier den Anfang und das Ende zu finden, kann man über "bedingte Auswahl" die Spalte mit den Audiodaten (meist "Sensor-B:EMG (roh)" oder "Sensor-D:EMG (roh)") einfärben und nach der entsprechenden Farbveränderung suchen.
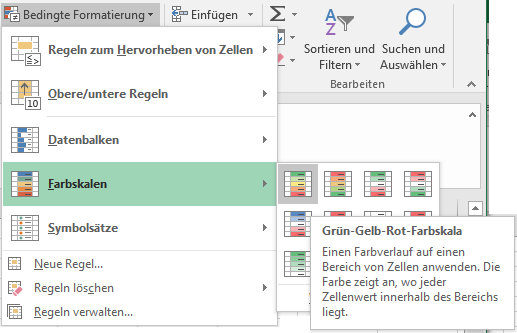
Farbskalenauswahl in der bedingten Formatierung
Dadurch wird der Beginn und das Ende des Audiobeispiels in den Daten schon in vielen Fällen erkennbar.
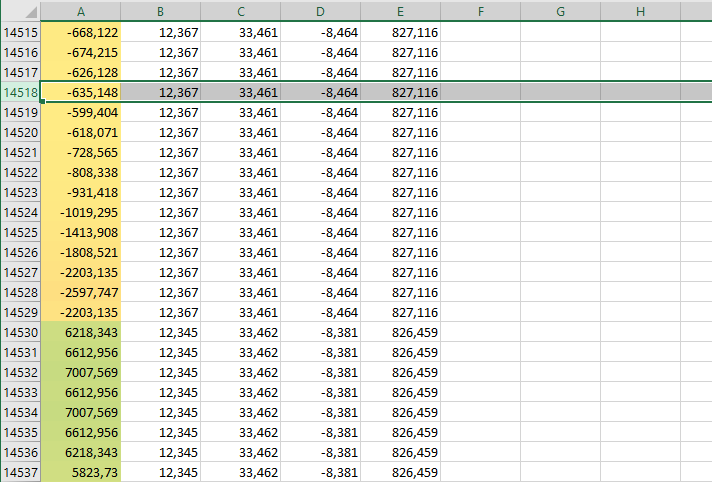
Beginn des Klangbeispiels (ab Z. 14519)
In
vielen Fällen ist der Übergang jedoch nicht so deutlich (vor
allem da bei Biotrace in den EXG-Kanälen = wo das Audiobeispiel aufgenommen
wird, Sampleraten bis zu 2048 Hz vorliegen).
Hier empfiehlt es sich über Einfügen -> Diagramme ein Liniendiagramm
über die Spalte mit den Audiodaten anzulegen, so dass Anfang und
Ende des Audiobeispiels dann meist ziemlich klar erkennbar sind ...

... und entsprechend gut geschnitten werden können, indem man die Zeilen hinter und vor dem Audiobeispiel löscht:
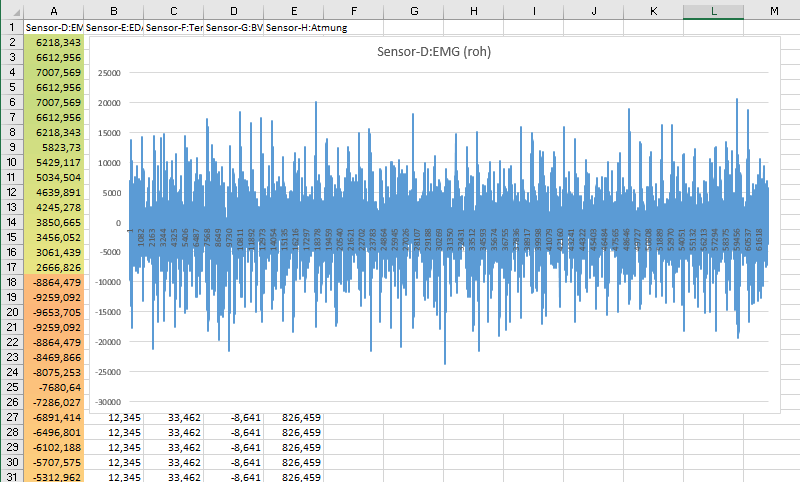
Die jetzt vorliegenden Daten können sowohl mit den physiologischen Daten anderer Versuchspersonen synchronisiert werden (-> Tabellen mit gleicher Größe bzw. Sample-Rate zusammenführen) als auch mit den Daten aus anderen Quellen (wie z.B. den SInEs Tools) zusammengeführt werden (-> Tabellen aus Biotrace mit unterschiedlicher Größe bzw. Sample-Rate zusammenführen).
Tabellen mit gleicher Größe bzw. Sample-Rate zusammenführen
Hat
man mehrere Excel-Dateien (z.B. die Hautleitwerte
von mehreren Versuchspersonen als txt.- oder csv-Datei), so müssen
sie vorher synchronisiert werden. Hierzu kann man sich am besten an der
Audiospur orientieren (beim Nexus-10MKII über einen der EXG-Kanäle
aufgenommen).
Hierzu nimmt man zunächst die Excel-Daten....
Hautleitwerte von Vpn1 und Vpn2 in Excel
...entfernt alle überflüssigen Informationen und beschriftet die Spalten eindeutiger ...
Hautleitwerte von Vpn1 und Vpn2 in Excel gesäubert und mit verständlicheren
Überschriften
... und ersetzt via Suchen/Ersetzen alle Punkte durch Beistriche.

Hautleitwerte
von Vpn1 und Vpn2 in Excel als Dezimalwerte
Nun kann man die Amplitudenwerte via Bedingte Formatierung ...
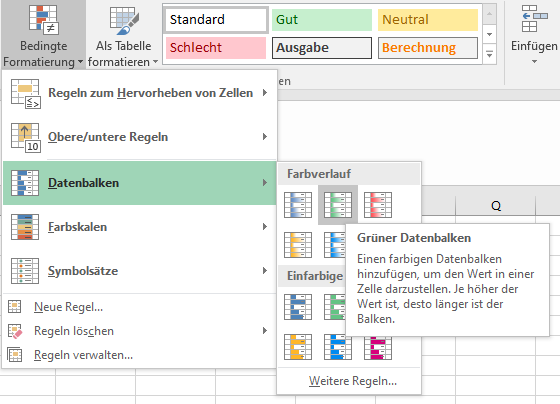
Auswahl Bedingte Formatierung in Excel
...
als Balken bzw. Kurven visualisieren und darüber optisch die Zeitpunkte
ermitteln, an denen das Klangbeispiel bei den jeweiligen Versuchspersonen
einsetzte (für einen prägnanteren Start des Klangbeginns bietet
es sich an, die Klangbeispiele am Anfang mit einem Knack zu versehen).
Für eine genauere Ansicht sollte man in Excel über Einfügen
-> Diagramme ein Liniendiagramm über die EEG-Spalte anfertigen,
so dass Anfang und Ende des Audiobeispiels klar erkennbar sind ...
Werte der Audiodaten, Anfang und Ende sind klar erkennbar
... und entsprechend gut geschnitten werden können, indem man die Zeilen hinter und vor dem Audiobeispiel löscht:
Werte der Audiodaten getrimmt
So hätten dann die Tabellen vergleichbare Anfangs- und Endpunkte:
Hautleitwerte von Vpn1 und Vpn2 in Excel mit gemeinsamen Startpunkten
des Klangbeispiels
Nun können beide Tabellen am jeweiligen Startpunkt zu einer Tabelle zusammengeführt werden ....
Hautleitwerte von Vpn1 und Vpn2 in Excel in einer Tabelle zusammengeführt
... und am Ende des Klangbeispiels entsprechend abgeschnitten werden.
Hautleitwerte von Vpn1 und Vpn2 in Excel in einer Tabelle zusammengeführt
mit gemeinsamem Ende
Da man für die gemeinsame Darstellung der Hautleitwerte nur eine Zeit und nur eine Amplitude braucht, können Zeit und Amplitude bei der zweite Vpn (bzw. bei allen anderen Vpns, wenn man mehrere Tabellen zusammenführt) auch weggelassen werden.
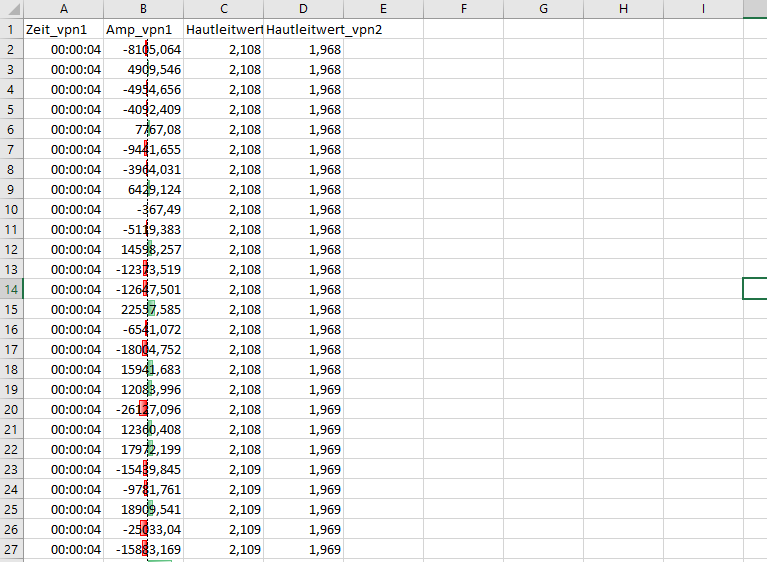
Hautleitwerte von Vpn1 und Vpn2 in Excel bezogen auf eine Zeit und eine
Amplitude
Tabellen aus Biotrace mit unterschiedlicher Größe bzw. Sample-Rate zusammenführen
Bei Tabellen mit unterschiedlicher Größe (= unterschiedlicher Zeilenlänge) öffnet man zunächst die größere Tabelle (meist die Excel-Tabelle aus dem Biotrace-Export), beschriftet das Tab an der unteren Leiste der Tabelle (z.B. "groessere_Tabelle") und legtdaneben ein neues Tab für eine neue Tabelle an (z.B. "kleinere_Tabelle").
Zwei Tabellen an der unteren Leiste von Excel
in
der kleineren Tabelle schreibt man in die erste Zeile/erste Spalte (A1)
die Formel:
=INDEX(name_groessere_Tabelle!$A$1:$I$zeilen_groessere_Tabelle;
ZEILE() * ((zeilen_groessere_Tabelle-1) /
(zeilen_kleinere_Tabelle-1));
SPALTE())
($I ist in diesem Beispiel die letzte Spalte der größeren Tabelle)
Wenn die größere Tabelle "groessere_Tabelle" heisst und 61507 Zeilen hat und die kleinere Tabelle 602 Zeilen hat, dann lautet die Formel:
=INDEX(groessere_Tabelle!$A$1:$I$61507;ZEILE()*(61506/601);SPALTE())
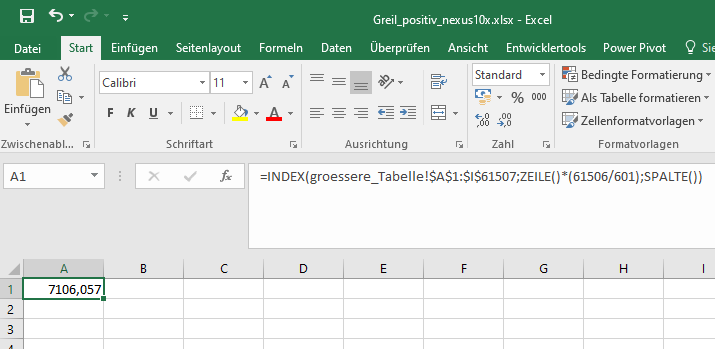
Formel zur Anpassung von zwei unterschiedlich großen Tabellen
Am Anfasser der Zelle (rechts unten im grünen Rahmen) erweitert man dann die Zelle über die ganze Zeile:
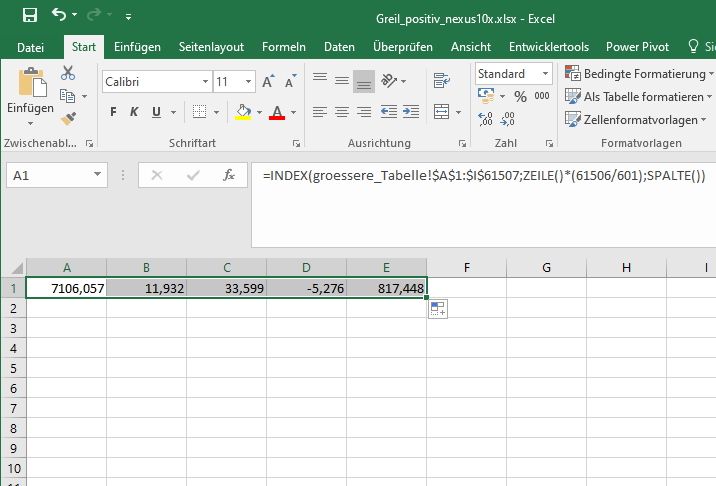
Zelle mit der Formel auf die Zeile erweitern
Danach erweitert man die Tabelle am Anfasser, bis man die Zeilenanzahl der kleinen Tabelle erreicht hat (Zeilen darüber hinaus erhalten den Wert "#BEZUG").
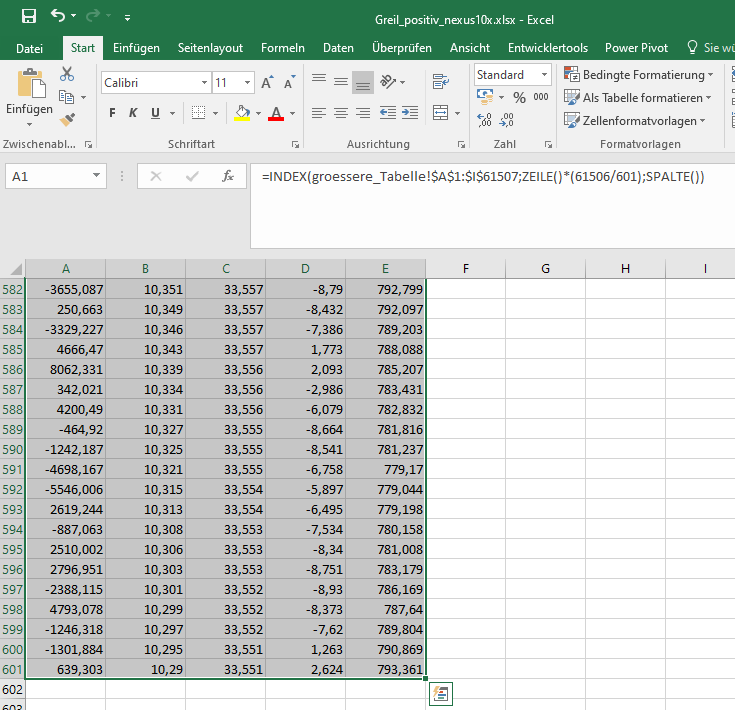
Zeile mit
der Formel über die ganze Tabelle erweitern
Bevor man die neue reduzierte Tabelle in die kleinere Tabelle kopiert, müssen die Formeln in den einzelnen Zellen noch in ihre eigentlichen Werte umgewandelt. Dafür wählt man alle Zeilen aus und kopiert sie mit STRG+C. Über "Start -> Einfügen: Werte Einfügen" werden die Formeln in den Zellen durch ihre Werte ersetzt.
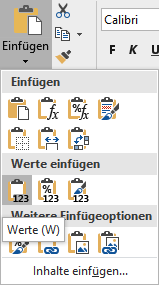
Werte anstelle der Formeln einfügen
Danach
kann man die gekürzte Tabelle in die kleinere Tabelle einfügen
und muss dann nur noch die Spaltenbezeichnungen in der ersten Zeile ergänzen.
zusammengeführte Tabellen
Werte in Excel normalisieren (Z-Score errechnen)
Wenn verschiedene Skalierungen miteinander verglichen werden sollen (z.B. Frequenzen von 20-20000 Hz und Helligkeit von 0-1), lassen sich diese meist nicht auf vergleichbaren Skalen darstellen bzw. es wird schwierig zu erkennen, ab wann ein Unterschied groß genug ist, um auffällig zu sein.
Aus diesem Grund lassen sich Skalen über den Z-Score normalisieren.
Der Z-Score gibt an, wie weit sich ein Wert von einem Mittelwert entfernt.
Die Einheiten im Z-Score sind Standardabweichungen (= durchschnittliche
Entfernung aller gemessenen Werte vom Mittelwert).
Um z.B. die Zahlenwerte aus einem Biotrace-Export mit Audiofeatures normalskaliert vergleichen zu können, benötigt man zunächst den Mittelwert und die Standardabweichung der Zahlenreihe:
Die Formel für den Mittelwert ist:
=MITTELWERT(Anfang_der_Reihe:Ende
der Reihe)
(im englischen geht auch =AVERAGE(Anfang_der_Reihe:Ende
der Reihe) )
Die Formel für die Standardabweichung ist
=STABW.N(Anfang_der_Reihe:Ende
der Reihe)
(im englischen geht auch =STDEVPA(Anfang_der_Reihe:Ende
der Reihe) )
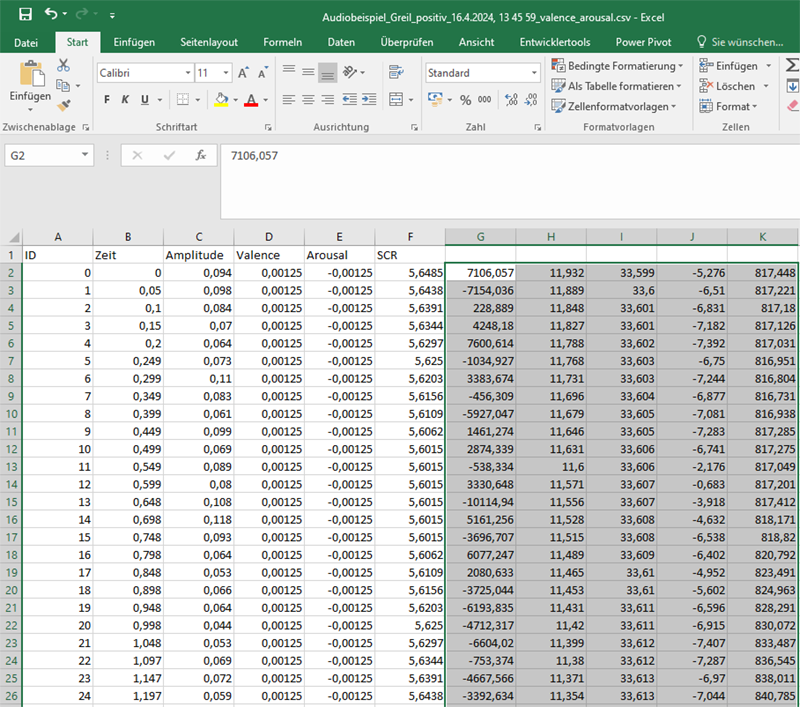
Wenn z.B. die Reihe von den Zellen B2 bis B62647 geht, dann würden die Formeln lauten:
=MITTELWERT(B2:B62647) und =STABW.N(B2:B62647)
Mittelwert und Standardabweichung einer Zahlenreihe
Der Z-Score errechnet sich nun aus dem jeweiligen Wert in der Zelle minus dem Mittelwert und das Ergebnis dann geteilt durch die Standardabweichung, also
=(Wert_aus_einer_Zelle_der_Zahlenreihe - Mittelwert) / Standardabweichung
Als Formel für Excel bedeutet das, wenn der Mittelwert in der Zelle B62650 ist und die Standardabweichung in der Zelle B62651 z.B. für den Wert in Zelle B62647:
=(B62647 - B62650)/B62651
Um den Z-Score für alle Werte in der Spalte zu rechnen legt man eine neue Spalte an, schreibt in die oberste Zeile "Z-Score" (o.ä.) und in die Zeile darunter
=(B2 - $B$62650)/$B$62651
Die $-Zeichen braucht man, damit die Zellen für Mittelwert und Standardabweichung immer die gleichen bleiben, wenn man die Formel in andere Zellen kopiert.
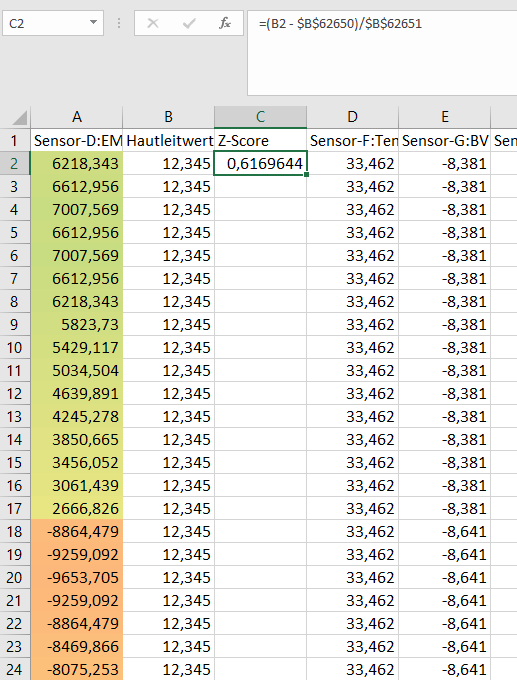
Errechnen des Z-Score in Excel
Nun kann man mit dem Anfasser (rechts unten am grünen Rahmen der Zelle) die Formel auf alle anderen Zellen der Spalte übertragen:
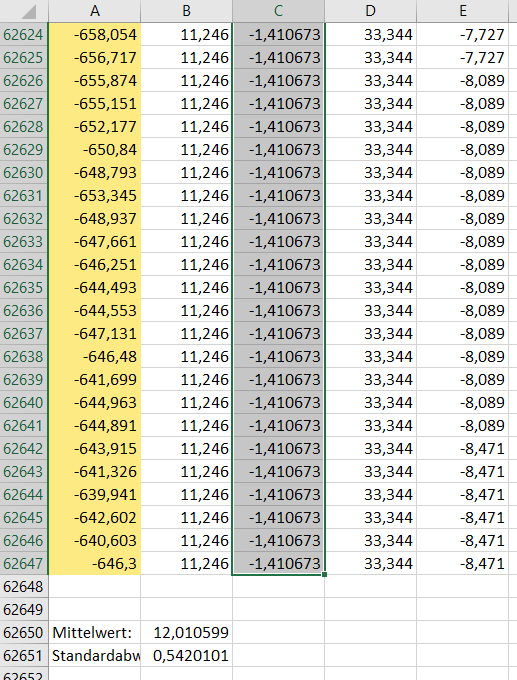
Spalte mit dem Z-Score der Werte in der Spalte links daneben
Ergebnisse (t-Tests, Korrelationsanalyse) aus JASP in Excel nach ihrer Stärke ordnen
JASP liefert zwar schnell eine Reihe von Ergebnissen, jedoch ist häufig nicht auf dem ersten Blick erkennbar, wo die stärksten Korrelationen oder die stärksten Unterschiede liegen. Hierfür bietet es sich an, die Ergebnisse aus JASP nach Excel zu kopieren und dort nach Signifikanz (p) und Korrelation (r) bzw. Unterschied (t) zu ordnen:
Hierfür kopiert man zunächst via (linken) Mausklick auf den Titel der Ergebnistabelle den Inhalt der Tabelle ...
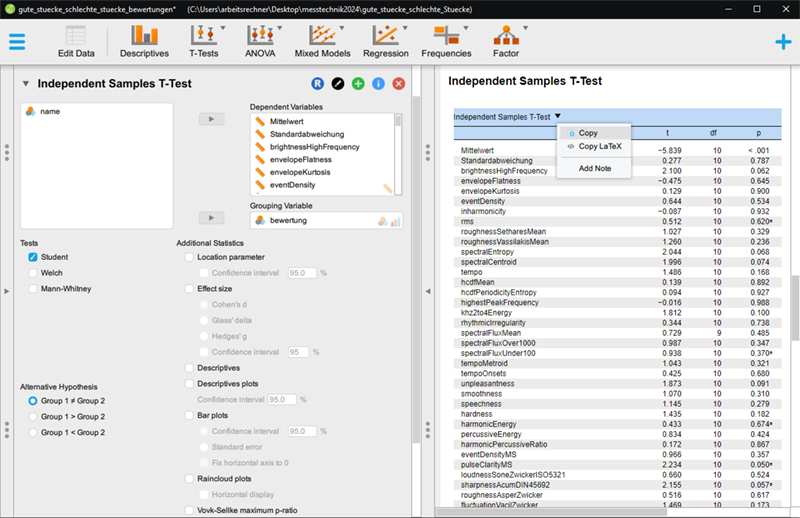
Kopieren der Ergebnistabelle in JASP
...nach Excel...
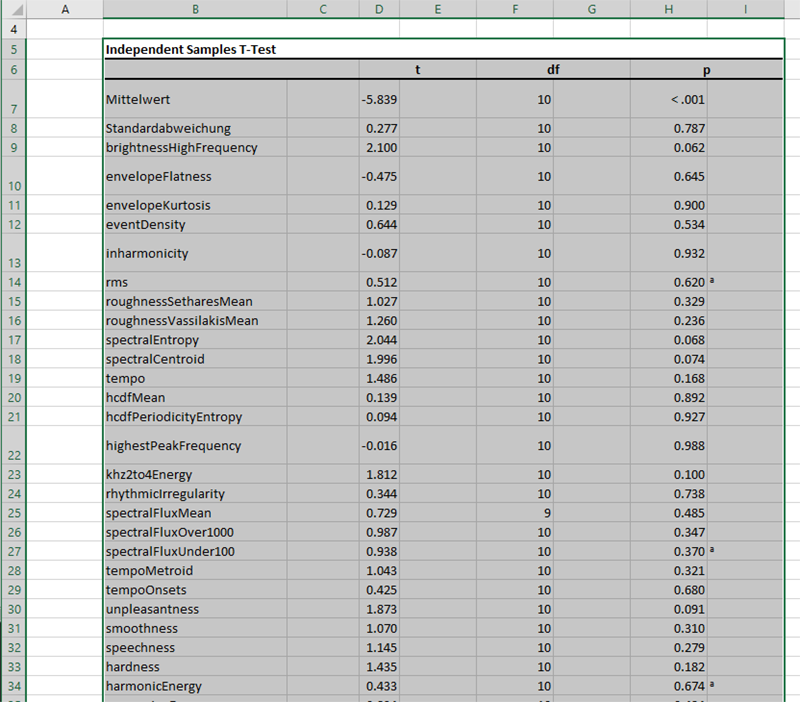
Einfügen der Tabelle in Excel
... und ersetzt dort alle Punkte durch ein Komma ...
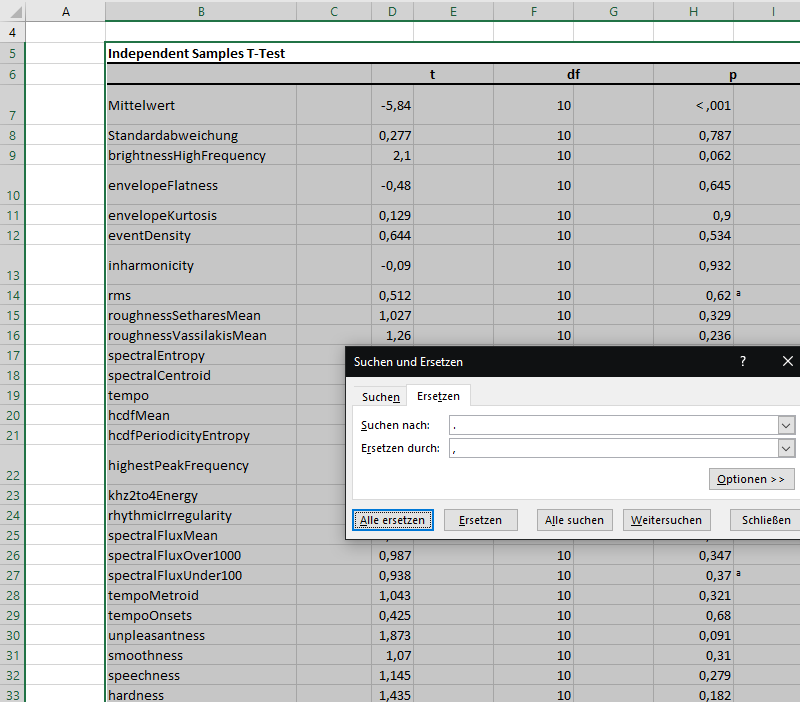
Punkte durch Beistriche ersetzen
... und entfernt unter rechte Maustaste -> "Zellen formatieren" im zweiten Reiter des Dialogfensters ("Ausrichtung") alle Haken/Einträge bei "Zeilenumbruch" und "Zellen verbinden".
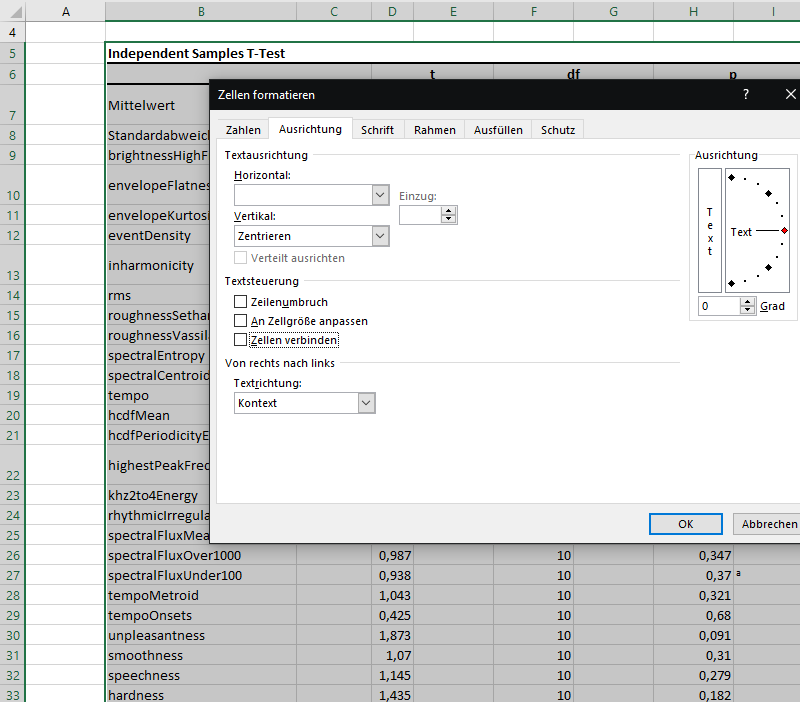
Formatierung von JASP aufheben
Danach löscht man alle leeren Spalten (beim t-Test inklusive "df"), so dass die Tabelle kompakt vor einem liegt.
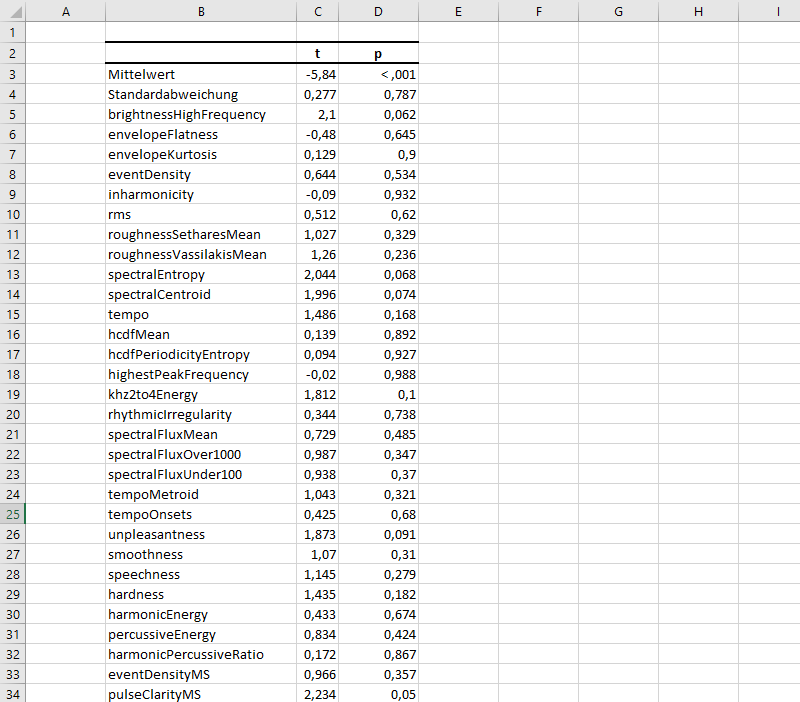
Tabelle reduziert auf Variable, t und p
Über STRG+A und einem Klick in die Tabelle wählt man die gesamte Tabelle aus und geht über "Start -> Sortieren und Filtern" auf "Benutzerdefiniertes Sortieren"....
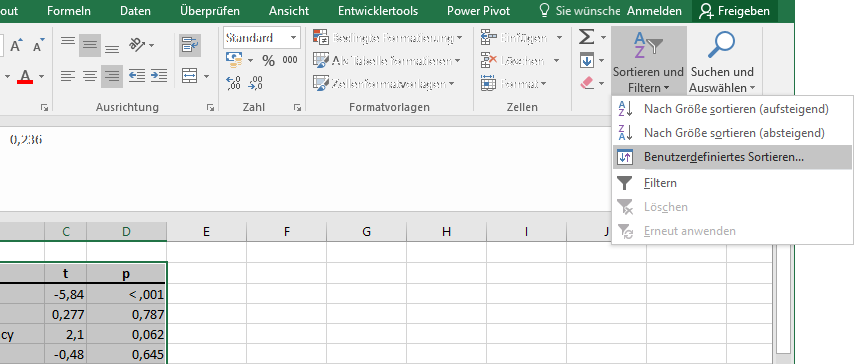
Tabelle auswählen und "Benutzerdefiniertes Sortieren" öffnen
... und sortiert zunächst nach "p" (in der Reihenfolge "Nach Größe (absteigend)"). Danach lassen sich bequem alle Zeilen löschen, in denen p >= 0,05 ist.
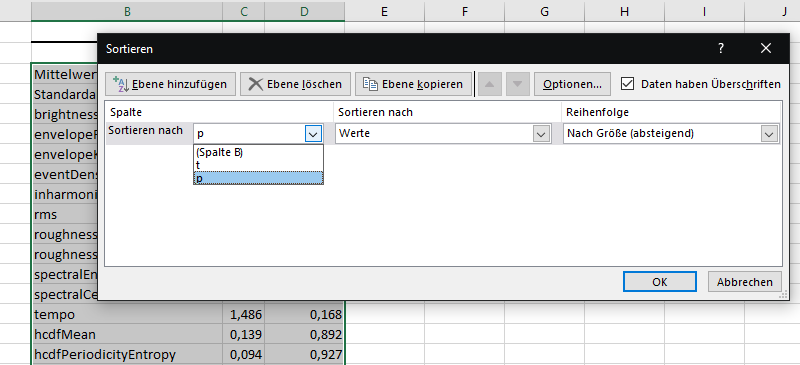
Nach p in absteigender Reihefolge sortieren
Dann wählt man wieder die übriggebliebene Tabelle mit STRG+A aus und öffnet über "Start -> Sortieren und Filtern" mit "Benutzerdefiniertes Sortieren" dass entsprechende Dialogfenster und sortiert dann nach "t" bzw. "Pearsons' r" (in der Reihenfolge "Nach Größe (absteigend)").
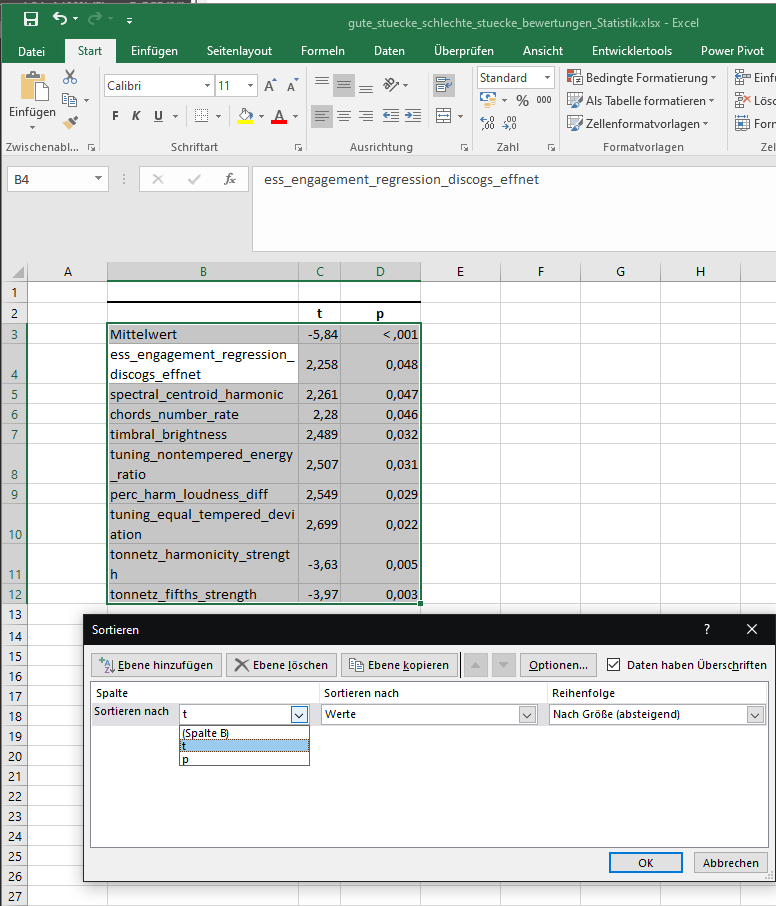
Nach p in absteigender Reihefolge sortieren
Dann hat man alle Unterschiede (t) oder Korrelationen (r) nach ihrer Größe geordnet vorliegen und kann die entsprechende Spalte auch via "Bedingte Formatierung" zur besseren Übersicht noch einfärben.
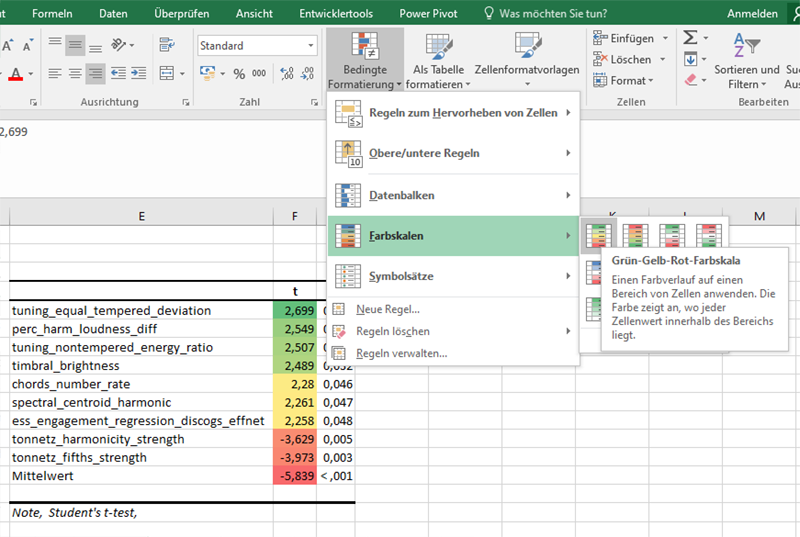
Tabelle mit allen signifikanten t-Werten in absteigender Reihenfolge